The story below details a very interesting & transformational project that I was a part of in 2014 and 2015, at a Dutch company. I’ve told this story before during a number of conference talks (slides and videos are available, if you’re interested), and I’ve now finally come around to writing it up as a series of blog posts!
This is part 1 of a multipart series on how CD, DevOps, and other principles were used to overhaul an existing software application powering multiple online job boards, during a project at a large Dutch company.
Introducing the project & “the ball of mud”
This project was undertaken in the north of Amsterdam, along the river IJ, at a large Dutch company.

This company operates a number of well known, online job boards. On these sites, recruiters and organizations alike can list vacancies, search for matching candidates and download resumes. Individuals on the other hand can upload resumes, list their availability, interests and other data, and search for interesting opportunities.
When I arrived, as an external consultant, the company was dealing with a situation which many of you are probably familiar with. The web application running the various job boards, mostly written in PHP, was in need of serious overhaul. While generating significant income, it was a complicated, almost untested, aging and lethargic beast of a monolith: a typical ball of mud (or spaghetti). Slow page loads (north of six seconds) were painfully common, and, as a result of years of organic growth, takeovers and (understandable) shortcuts, the application had become very complicated to maintain, let alone develop.
This amount of technical debt meant the responsible team was constantly hunting bugs, fighting fires and hindered by a general lack of confidence in how to deal with and improve the system.
The architectural picture
Let’s take a look at (a slightly simplified version of) the architecture of the system, code-named “Berlin”.
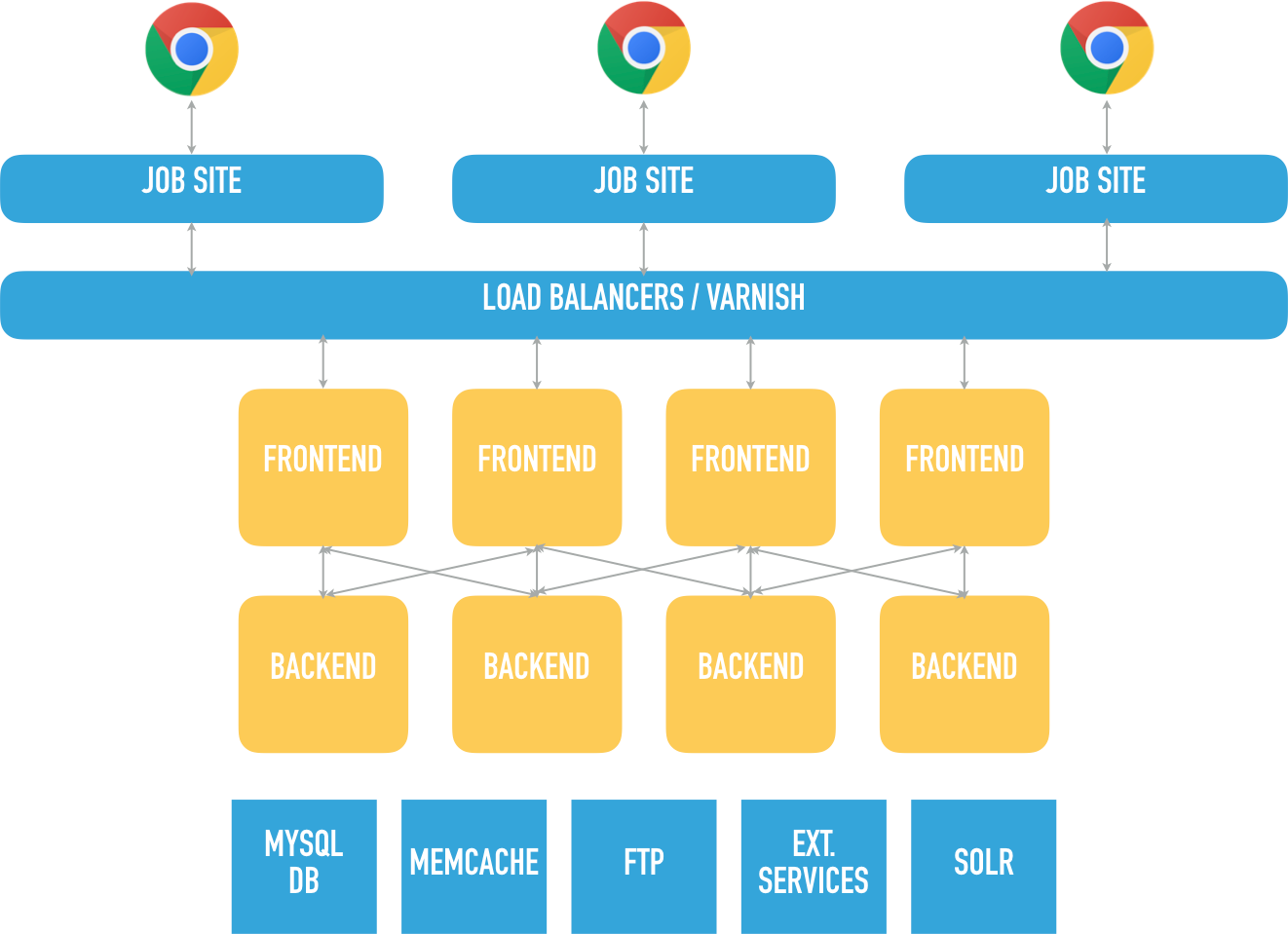
As I wrote earlier, the company in question operates a number of online job boards. These boards are marketed as individual sites (brands), but were actually all served by the same web application.
Traffic for the individual sites flows from the internet into a bunch of load balancers, which then pass it on to a tier of caching servers, running varnish.
Whatever content can not be found in the caches is retrieved from one of the servers in the front-end tier, which talk to various servers in the back-end tier. So far so good, and a very typical architectural picture.
However, things start to get interesting when we look at the way the front-end servers communicate to the back-end servers. About three different methods are used: calls to a RESTful api (accessed through a varnish caching layer), remote procedure calls but also direct database access. To boot, both tiers of servers run the exact same application code. The only thing differentiating a front-end server from a back-end one is a single flag, otherwise they are identical.
Release schedule
The release schedule as I encountered it when I started on the project was what I can only call “flexible”. The team responsible for the application deployed new versions into production roughly every four to five weeks. Releases were only scheduled when there was “enough” functionality developed, a decision made by a handful of people (typically involving QA).
Releases typically only occurred in weekends, except for “hot fixes” or other critical bug patches that needed to occur during workdays. The release procedure required taking the web application offline (or putting it in maintenance mode), which meant that all job board sites were unusable.
Now, a key characteristic of an online job board – especially in this case – is that such a site typically serves two groups of users.
One is the group of recruiters, employers, agencies, etc. that pay money to add their job listing to the site(s), or be able to search through an archive of CV’s. They are generally active on the site on working days, weekdays from 9 to 5.
The second group is composed of people that are looking for a new or better job. Typically, those folks interact with a job board in their private time, usually at night and in weekends.
Thus, taking a job board offline during a weekend directly impacts that latter group. Of course, the group of paying users mostly isn’t directly affected. But in terms of user satisfaction and reviews, it definitely wasn’t ideal.
Release stability
Next to that was the issue of release stability. While there were tests, the ones that did exist were so fragile (randomly failing, timing out, dreadfully slow in some cases) that their results were frequently ignored. To make matters worse, some parts of the application were completely uncovered by automated tests, or tests were written at the wrong level of abstraction.
Manual testing was performed by the QA people present, but often (due to time constraints) limited to specific areas of the code. Thus, there was a high rate of defects and issues popping up in the code deployed to production. All in all, this led to the team regularly debugging issues, fighting outages and dealing with brush fires in the days after a release.
Moving forward
A situation like this, while it existed for quite a while, can not be allowed to go on much longer; lest the company face serious issues.
Here we have an application that has organically grown to its current size and complexity. It is wrought with technical debt and maintained by a team that’s mired in a swamp, filled with firefighting, outages and development that’s taking way longer than it should.
All this means that the company was not able to quickly and effectively react to the market, innovate and deliver value. While the company (and its parent) had a certain scale and market share, the online job board market is very competitive and fast-moving, and even the biggest companies can be easily disrupted.
Goals & options
To counter this, management intended to move the company to a place where it could start innovating again, and taking the lead again. This meant significantly improving on the company’s ability to service end-users (whether they are recruiters or jobseekers), and generally increase end-user satisfaction. To reach that place, a few goals were outlined:
- Improve stability & quality; significantly reduce the number of issues and outages that are costing valuable developer time.
- Reduce the lead time to production: the time for an idea to be developed, put into production and be usable by a customer. For the existing application, this could be measured in terms of three of four months for relatively simple functionality.
Next to those goals, two additional , more or less following from the main goals:
- Improve (developer) productivity: when developers and other members of the team don’t spend as much time dealing with issues and firefighting, they can spend more time on better understanding customers’ needs, and delivering value.
- Increase team motivation (and potentially retention): a company that actually spends time to get its affairs in order, listens to its employees, rewards them well, and above all lets them work on cool things, has a better chance of retaining those employees (and attracting additional people).
Clearly, the existing application and way of working were incapable of supporting those goals, and both had to be significantly overhauled if there was any chance of success.
A first attempt at refactoring the application was made, enthusiastically, for a few months. This indeed led to a dramatic increase in test code coverage, jumping to 2.5% on a 500k+ loc application. While impressive, it wasn’t nearly enough to continue doing linearly, and other options needed to be considered.
The Big Bang Theory: rewriting?
When refactoring turned out not to be an option (realistically), a central question was posed: do we buy or build. And if we build, in what way?
In this context, “buy” means acquiring and implementing a commercial off-the-shelf (COTS) job board from a vendor and discontinuing the existing development team. This was considered and discounted on the basis that, if you buy and implement a COTS job board, you get a standard job board that’s probably customizable in a number of ways, but it will never be your product, and you will never be able to really innovate on it, beyond what the vendor can or will deliver. Indeed, vendors don’t have the same goals or interests as the company that’s buying their products.
So, no refactoring, and no COTS product. Next, we thought about rebuilding the application as part of a cut-over rewrite. This basically means you write an entirely new application, alongside the existing one. When the new application has reached feature parity with the existing application (it has the exact same functional specs and responds the same), you flip a switch and start using the new application.
One of the problems with such a rewrite – apart from the obvious one that big bang releases never fail to, well, fail – you end up copying all of the bugs that are in the existing system, and that over time have actually become features. The why behind a lot of existing functionality is lost: documentation was never updated, decisions weren’t recorded, the people involved have long since left the company, etc. A cut-over rewrite ends up rebuilding all sorts of unneeded functionality, because it’s hard to decipher what’s needed or not needed.
Part 2 of this series is now available here: The Road to Continuous Deployment (part 2)
Pingback: The Road to Continuous Deployment (part 2) - Michiel Rook's blog